Node.js 宣称其目标是“旨在提供一种简单的构建可伸缩网络程序的方法”,诞生自 2009 年,是有史以来发展最快的开发工具,它是运行环境而不是语言。如今 Node 的使用已经较为普遍,所在团队的后端微服务架构中,80% 都是 Node 服务,近一两年做了不少 Node 后端的开发,下一阶段学习计划是 Go 的学习和实践,所以有必要整理下Node的经历和累积。
为了简洁明了更加直观,采用互动性强的 QA 方式汇总。
Node 的历史
Q:请简单说下 Node 的发展历史?
Node 的创始人 Ryan Dahl 的工作是用 C/C++ 写高性能 Web 服务。对于高性能,异步IO、事件驱动是基本原则,但是用 C/C++ 写着实痛苦,于是他参考诸多高级语言,终选定 JavaScript,在2009年,Ryan及其团队正式推出了基于 JavaScript 语言和 V8 引擎的开源 Web 服务器项目,命名为 Node.js。
Node 第一次把 JavaScript 带入到后端服务器开发,成为了世界上无数 JavaScript 开发人员的宠儿,开始茁壮成长,期间 Node.js 的核心用户 Isaac Z. Schlueter 开发出奠定了 Node.js 如今地位的重要工具——NPM。
Node.js 基金会成立后,其生态逐渐扩张,connect, express, socket.io 等开源库层出不穷,一大波以 Node.js 作为运行环境的 CLI 工具涌现,其中不乏有用于加速前端开发的优秀工具,如 less, UglifyJS, browserify, grunt 等等。
大量新功能、新技术、新实践伴随 Node 版本更迭被引入,发布了LTS版本,核心 API 趋于稳定,随著 ES2015 的发展和最终定稿,一大批利用 ES2015 特性开发的新模块出现,如原 express 核心团队所开发的 koa等,Node 生态愈加完善,大型企业级应用的实践愈加成熟。
Node 的特性
Q:Node.js 有哪些特性?
异步事件驱动
非阻塞I/O
轻量、可伸缩,适于实时数据交互应用
单进程,单线程(这里指主线程)
性能出众 (依赖 Chrome V8 引擎解释,是一个多线程平台、运行环境,对 JavaScript 层面的任务处理是单线程的)
多进程与多线程
Q:聊一下你对进程、线程的了解?
进程:资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。(程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行)
线程:线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。(线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理)
Q:线程和进程有什么区别和优劣呢?
概念:进程是资源分配的最小单位,线程是程序执行的最小单位。
资源消耗:进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
通信方便:进程之间的通信需要以通信的方式(IPC)进行,而线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据。
健壮性:多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
任务类型(I/O-bound 和 CPU-bound, macrotask 和 microtask)
Q:在高并发、多线程编程中经常会听到两个密集型,请解释下。
I/O密集型 (I/O-bound):
- 主要是进行网络、硬盘、内存的IO操作,执行IO操作的时间较长,导致CPU的利用率不高;
- 此时系统运作状况为 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高,CPU处于空闲状态、消耗很少;
- 例如数据库增删改查操作、文件读写、访问I/O设备等;
- 常见的大部分任务都是IO密集型任务,比如Web应用。
计算密集型 (CPU-bound):
- 主要是执行计算任务,响应很快,CPU一直在运行,这种任务CPU的利用率很高;
- 此时系统运作状况为 CPU Loading 100%,主要消耗CPU资源,I/O在很短时间就可以完成;
- 例如斐波那契数列等复杂计算,对数据加解密,数据压缩和解压,长时间循环计算,对视频进行高清解码等;
- 大部分CPU占用率超高的任务是此类型,这可能因为任务不太需要访问I/O设备,也可能因为程序是多线程实现而屏蔽掉了等待I/O的时间。
适用语言:计算密集型程序适合C语言多线程,I/O密集型适合脚本语言开发的多线程。
Q:浏览器环境中异步任务有哪些宏任务和微任务
宏任务(macrotask): setImmediate、I/O、MessageChannel、postMessage、点击事件的callback、UI渲染、setTimeOut、setInterval等。
优先级:script(全局任务)即主代码 > setImmediate > MessageChannel > setTimeOut/setInterval
特点:宏任务队列每次只会取出一条任务到执行栈中执行。
Vue 中对于 macro task 的实现:优先检测是否支持原生 setImmediate,这是一个高版本 IE 和 Edge 才支持的特性,不支持再检测是否支持原生的 MessageChannel,如果也不支持的话就降级使用 setTimeout 0
微任务(microtask):process.nextTick (非浏览器 Node 环境才有) 、Promise 、MutationObserver(HTML5特性)、Object.observer、async(实质上是Promise)、vue.$nextTick
优先级:process.nextTick > Promise > MutationOberser
特点:微任务队列操作,总是会一次性执行直到清空队列。
Vue 对于 microTask 的实现:Vue.$nextTick 并不一定是微任务,这取决于这个函数采用 Promise/MutationObserver 还是setTimeout 实现,当前环境若不支持 Promise,然后也不支持MutationObserver(2.5+版本后由于兼容性弃用,使用 MessageChannel 替代),则降级采用 setTimeout 0 实现。
2.4版本前:Vue.$nextTick 几乎都是基于 microTask 实现的,采取的策略是默认走microTask,但是由于microTask的执行优先级非常高,在某些场景下它甚至要比事件冒泡还快,就导致一些诡异的问题;但如果全改成 macroTask,对一些有重绘和动画的场景也会有性能的影响。
2.5+版本后:Vue.$nextTick 采取的策略是默认走 microTask,对于一些DOM的交互事件,如v-on绑定的事件回调处理函数的处理会强制走 macroTask,而 Vue 对于 macro task 的实现,上面已经说过了。
EventLoop中分为 内存、执行栈、WebApi、异步回调队列,而异步回调队列则包括微任务队列和宏任务队列。
浏览器的EventLoop执行流程:
-> JS 内核加载代码到执行栈。
-> 执行栈依次执行主线程同步任务,并将异步任务加入异步回调队列。(宏任务事件压入宏任务队列、微任务事件压入微任务队列)
-> 执行栈代码执行完毕,一次性执行当前微任务队列所有回调事件,直到清空队列。
-> 取出宏任务队列第一条放入执行栈执行,执行过程在遇到宏、微任务各自入队,本轮执行结束,往复循环上一步骤和本步骤,构成事件循环。
Q:为了合理最大限度的使用系统资源同时也要保证的程序的高性能,如何配置CPU密集型任务和IO密集型任务的线程数?
IO密集型:线程个数 = CPU核数 * 2。(好处:其中的线程在IO操作的时候,其他线程可以继续用CPU,提高了CPU的利用率)
CPU密集型:线程个数 = CPU核数 || CPU核数 + 1。(好处:这些线程可并行执行,不存在线程切换的开销,提高了CPU的利用率的同时也减少了切换线程导致的性能损耗。)
执行方式(串行、并行、并发、同步、异步、阻塞、非阻塞)
Q:如何理解串行、并行、并发的区别?
串行:同步线程的实现方式,多个任务按顺序执行,单个线程只能执行一个任务,一个任务执行完成才能执行下一个。
并行:真正的异步,多核CUP可以同时开启多条线程供多个任务同时执行,互不干扰。
并发:伪异步,在单核CUP中只能有一条线程,但又想执行多个任务,只能在一条线程上不停的切换任务。由于CUP处理速度快,貌似是同时执行,其实在同一时间只会执行单个任务。
Q:如何理解阻塞非阻塞与同步异步的区别?
同步和异步关注点在于消息通信机制。
同步调用:在发起一个调用后,调用者主动等待这个调用的结果,在没有得到结果前,该调用就不返回,但是一旦调用返回,就得到返回值了。
异步调用:一个异步调用发出后就直接返回了,但调用者不会立刻得到结果,而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
举例:以人工查话费账单为例,如果是同步通信,小李让客服A帮忙查话费账单,她可能马上查到,也可能很久,然后告诉小李结果。如果是异步,客服A会告诉小李等她查好会发短信通知,然后就挂电话。这里的短信回复便是回调。
阻塞和非阻塞关注点在于程序在等待调用结果(消息,返回值)时的状态.
阻塞调用:调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用:不能立刻得到结果之前,该调用不会阻塞当前线程。
举例:还以上述为例,如果阻塞式调用,客服A在帮小李查询到账单之前,小李会被挂起,一直等待结果返回,无法做其他的事情,而非阻塞式调用,小李不用管客服A有没有告诉他,小李可以去做其他的事,只需周期性的检查是否有短信回复。
所谓同步异步,只是对于客服A而言。 所谓阻塞非阻塞,仅仅对于小李而言。
运行机制
Q:JavaScript 运行机制是怎样的?(JavaScript的异步机制)
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个线程处理”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件,只要指定过回调函数,这些事件发生时就会进入”任务队列”,等待主线程读取。
一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”中的事件,并执行事件对应的异步任务(回调函数),该异步任务结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。如下图。
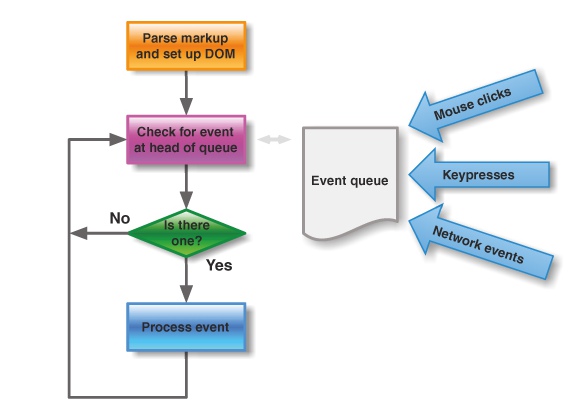
任务队列:是一个FIFO的数据结构,排在前面的事件,优先被主线程读取。它一个事件的队列(也可以理解成消息的队列),IO设备完成一项任务,就在”任务队列”中添加一个事件,表示相关的异步任务可以进入”执行栈”了。主线程读取”任务队列”,就是读取里面有哪些事件。
回调函数:指那些会被主线程挂起的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
事件:除了IO设备的事件以外,还包括一些用户产生的事件(比如鼠标点击、页面滚动等等)。如果”定时器”存在,主线程可能首先要检查一下执行时间,某些事件只有到了规定的时间,才能返回主线程。
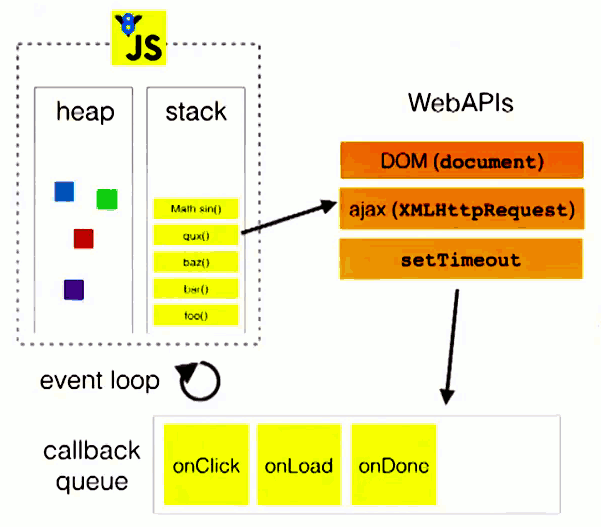
事件循环:主线程从”任务队列”中读取事件,这个过程是循环不断的,所以这种运行机制就称为 Event Loop。主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在”任务队列”中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取”任务队列”,依次执行那些事件所对应的回调函数。如下图。
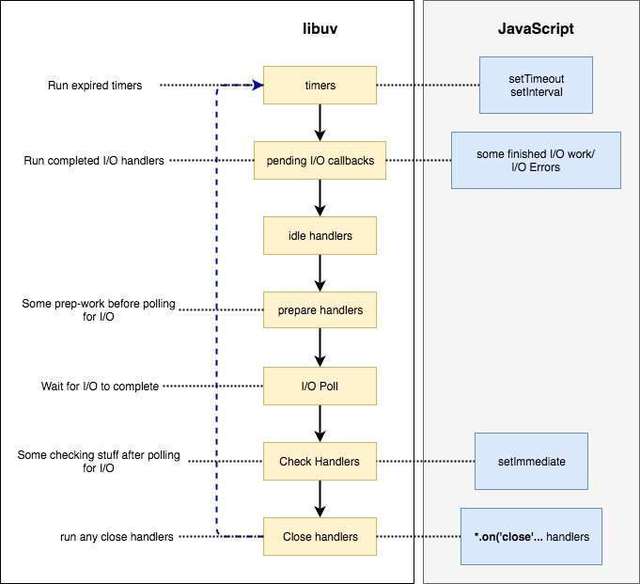
Q: Node.js的架构及运行机制是怎样的?
V8引擎解析JavaScript脚本。
解析后的代码,调用Node API。
libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
V8引擎再将结果返回给用户。如下图。
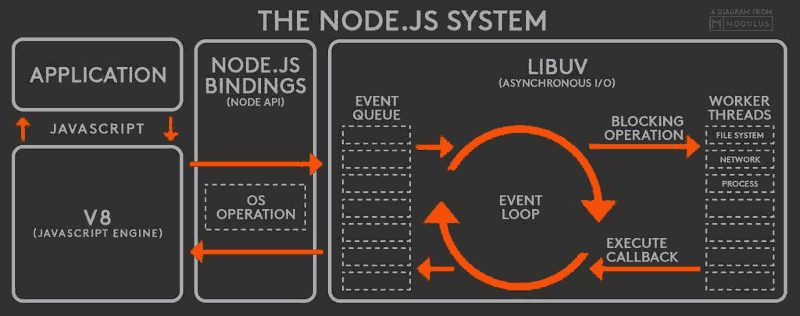
图解:
应用层:即 JavaScript 交互层,常见的就是 Node.js 的模块,比如 http,fs,https, util。
V8引擎层:即利用 V8 引擎来解析JavaScript 语法,进而和下层 API 交互。
NodeAPI层:为上层模块提供系统调用,一般是由 C 语言来实现,和操作系统进行交互, 比如 net, buffer, child_process, file。
LIBUV层:是跨平台的底层封装,实现了事件循环、异步IO,如文件操作等,是 Node.js 实现异步的核心。(libuv是一个高性能的,事件驱动的I/O库,并且提供了跨平台(如windows, linux)的API,被很多编程语言引入,如 Rust),他的事件循环中宏、微任务执行机制,如下图。
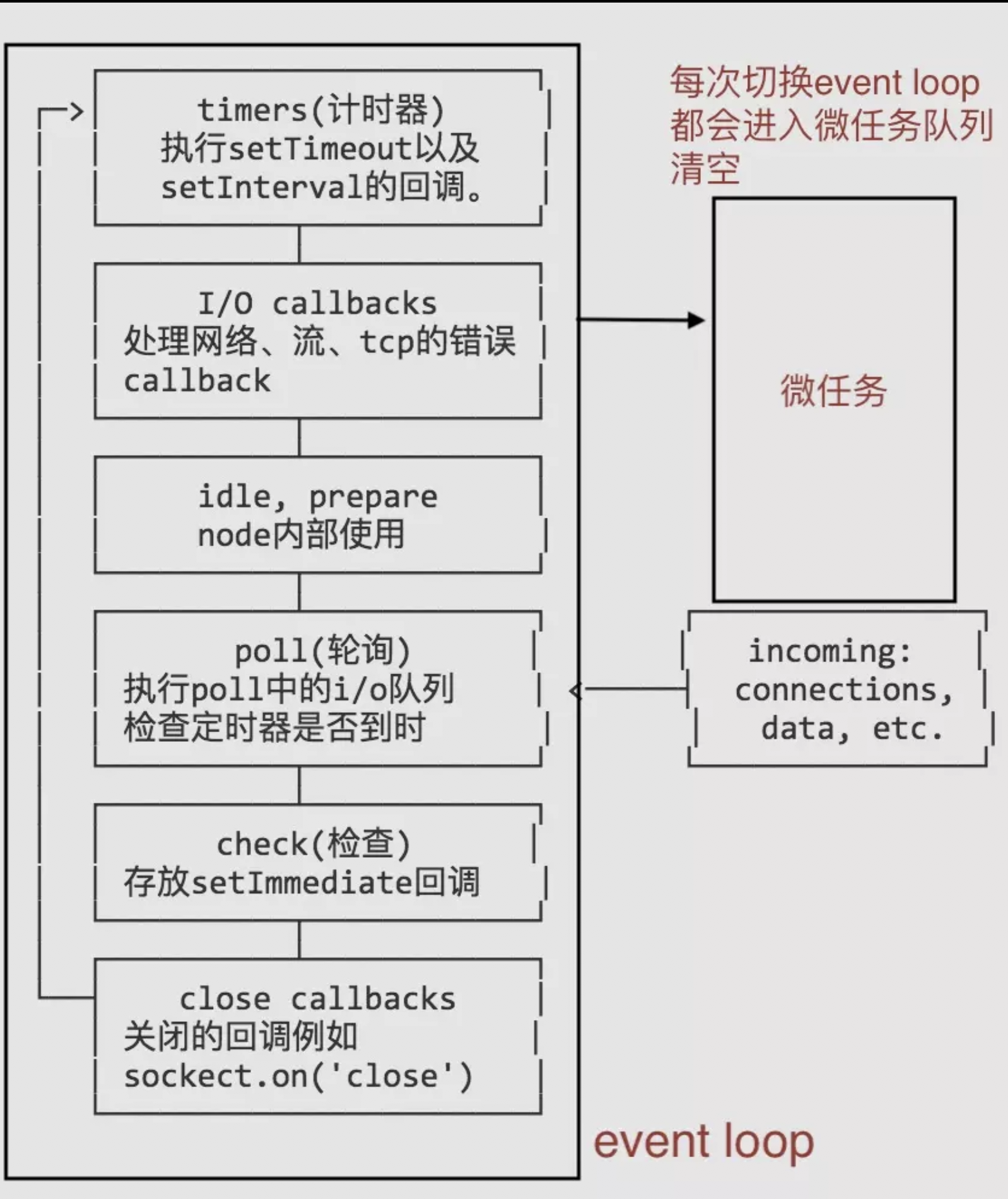
图解如下:
- 上面每个阶段对应着一个事件队列,当EventLoop执行到某阶段时,执行对应的事件队列中的事件,当该队列执行完毕或者执行数量超过上限,EventLoop就会执行下一个阶段。
- 每当EventLoop切换一个执行队列时,就会去清空microtasks queues,然后再切换到下个队列去执行,反复循环。
Q: Node 事件循环的运行机制是怎样的?
libuv :实现 Node.js 事件循环和平台的所有异步行为的 C 函数库
事件循环, 大体上分为6个阶段,执行顺序及内容如下图,建议去通读一下官方文档。
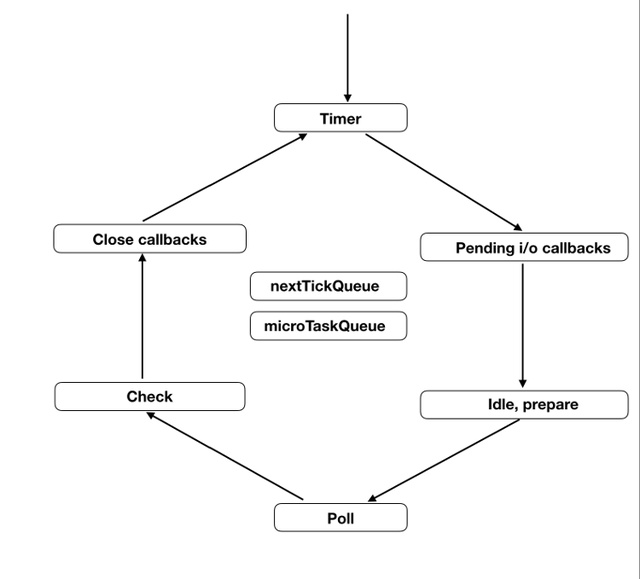
timers(定时器阶段)
定时器用途是让指定的回调函数在某个阈值后会被执行,具体的执行时间并不一定是那个精确的阈值。(定时器的回调会在制定的时间过后尽快得到执行,然而,操作系统的计划或者其他回调的执行可能会延迟该回调的执行。)
定时器阶段会处理setTimeout()和setInterval()的回调函数。进入这个阶段后,主线程会检查一下当前时间,是否满足定时器的条件。如果满足就执行回调函数,否则就离开这个阶段。
注:从技术上来看,轮询阶段控制了定时器的执行时机。
pending callbacks(pending 回调阶段)
执行延迟到下一个循环迭代的 I/O 回调,除了 setTimeout 和 setInterval 、setImmediate、用于关闭请求的回调函数,如socket.on(‘close’, …),其他的回调函数都在这个阶段执行。
执行的回调函数:几乎全部发生异常的 close 回调,由定时器和setImmediate()计划的回调,TCP错误之类的系统操作的回调。
idle, prepare (空闲,预备阶段)
该阶段只供 libuv 内部调用,分为 idle handlers 和 prepare handlers 两部分,prepare handlers 会为Poll阶段做些准备工作。
Poll(轮询阶段)
该阶段获取新的 I/O 事件,轮询时间等待还未返回的 I/O 事件,比如服务器的回应、用户移动鼠标等等。
该阶段时间较长,Node.js 这时会适当进行阻塞,如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 I/O 请求返回结果。
注:为了防止轮询阶段持续时间太长,libuv 会根据操作系统的不同设置一个轮询的上限。
轮询阶段有两个主要功能或过程:
- 执行已经到时的定时器脚本
- 处理轮询队列中的事件。
当EventLoop进入到轮询阶段,却没有发现定时器时:
如果轮询队列非空:
EventLoop会迭代回调队列并同步执行回调,直到队列空了或者达到了上限(前文说过的根据操作系统的不同而设定的上限)
如果轮询队列是空的:
如果有setImmediate()定义了回调:EventLoop终止轮询阶段,进入check阶段去执行setImmediate回调;
如果没有setImmediate():事件回调会等待回调被加入队列并立即执行。
总结:一旦轮询队列空了,事件循环会查找已经到时的定时器。如果找到了,事件循环就回到定时器阶段去执行回调。
check(检查阶段)
该阶段执行setImmediate()的回调函数。
setImmediate() 是个特殊的定时器,被设计成在一个单独的阶段运行, 它使用libuv的 API 来使得一旦轮询阶段完成就执行回调函数。
事件循环会最终进入到等待状态的poll阶段,可能是等待一个连接、请求等。然而,如果有一个setImmediate() 设置了一个回调并且poll阶段空闲了,那么事件循环会进入到check阶段而不是等待轮询事件.
close callbacks
该阶段执行关闭请求的回调函数,比如socket.on(‘close’, …)。
如果一个 socket 或句柄(handle)被突然关闭(is closed abruptly),例如 socket.destroy(), ‘close’ 事件会被发出到这个阶段。否则这种事件会通过 process.nextTick() 被发出。
详细图解如下
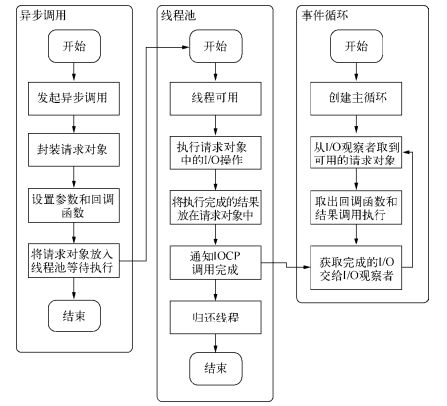
Q: Node.js的异步调用、线程池、事件循环之间关系是怎样的?(Node 异步 IO 处理流程)
异步机制:Node.js 在主线程里维护了一个事件队列,当接到请求后,就将该请求作为一个事件放入这个队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,就从 线程池 中拿出一个线程来处理这个事件,并指定回调函数,然后继续循环队列中的其他事件。
事件循环:当线程中的 I/O 任务完成以后,就执行指定的回调函数,并把这个完成的事件放到事件队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用。
定时器
Q: 说下 Node 的四个定时器?
process.nextTick:在当前”执行栈”的尾部,下一次Event Loop(主线程读取”任务队列”)之前,触发回调函数。也就是说,它指定的任务总是发生在所有异步任务之前。
setImmediate:在当前”任务队列”的尾部添加事件,也就是说,它指定的任务总是在下一次Event Loop时执行,这与setTimeout(fn, 0)很像。
setTimeout
setInterval
Node.js文档中称,setImmediate指定的回调函数,总是排在setTimeout前面。实际上,这种情况只发生在递归调用的时候。
Q:说下定时器的执行效率及区别?
执行效率:process.nextTick > setImmediate > setTimeout/setInterval
process.nextTick和setImmediate的一个重要区别:多个process.nextTick语句总是在当前”执行栈”一次执行完,多个setImmediate可能则需要多次loop才能执行完。事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取”事件队列”。
1 | process.nextTick(function foo() { |
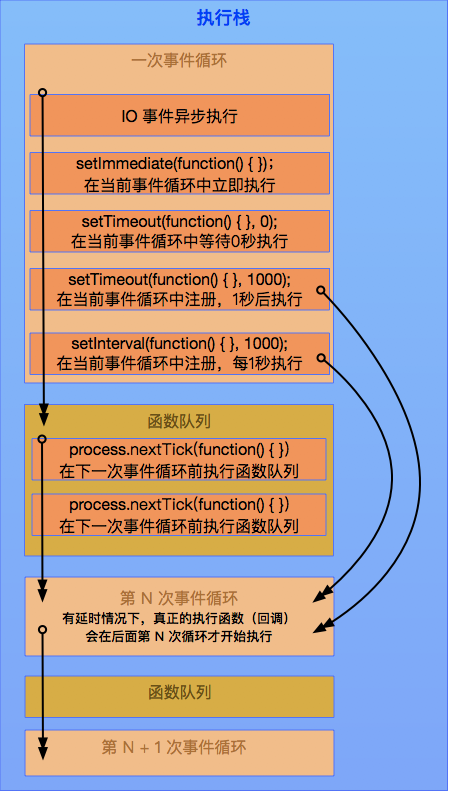
Q:Node 定时器在事件循环中的执行顺序是怎样的?
IO 事件是异步同时执行的,严格来说不在事件循环当中。
setImmediate、setTimeout、setInterval 都是在当前事件循环中注册,如有延时,比如1000ms, 真正的执行函数 callback, 会在后面第 N 次循环才开始被主线程执行。
一次循环只执行一个事件。
延时为0时,setTimeout、setInterval与setImmediate相同,在事件执行后可插入事件。
下一次循环前可插入一个函数队列,即执行多个 process.nextTick。
定时器在事件循环中的执行顺序如下图:
高并发
Q:请说下现有Web服务器的高并发策略、优劣、工作流程?
经典服务器模型:
每进程/每请求:提供多进程模型,为每个请求启动一个进程,这样可以处理多个请求,但是它不具备扩展性,因为系统资源只有那么多。
每线程/每请求:提供多线程模型,服务器为每个客户端请求分配一个线程,使用同步 I/O,系统通过线程切换来弥补同步 I/O 调用的时间开销, Apache采用这种策略。
Node 服务器模型:
事件驱动的方式处理请求,无须为每个请求创建额外的对应线程,省掉创建和销毁线程的开销,同时操作系统在调度任务时因为线程较少,上下文切换的代价很低。这使服务器能够有条不紊地处理请求,即使在大量连接的情况下,也不受线程上下文切换开销的影响,Node 采用这种策略。处理流程如下图。
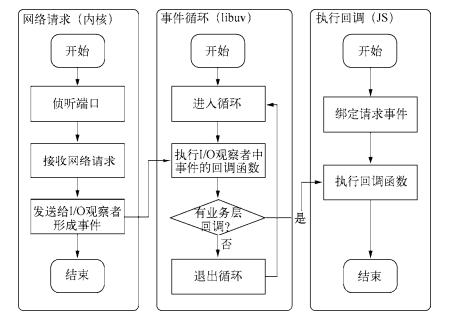
Node 优劣和适用场景
Q: 请说下 Node 的优劣势?
优点:
简单易学,JavaScript 前后端统一语言。
高性能,避免了频繁的线程切换开销。
线程安全,没有加锁、解锁、死锁这些问题。
占用资源小,因为对 JavaScript 层面的任务处理是单线程的,在大负荷情况下,对内存占用仍然很低。
社区活跃,生态资源丰富。
缺点:
很多包的成熟度不高,代码质量良莠不齐。
可靠性低、单进程,单线程,不能充分的利用多核CPU服务器。(该缺点可以通过代码的健壮性来弥补)
Q: 请说下 Node 的适用和非适用场景?
适用场景:
RESTful JSON API
聊天系统、微博系统等准实时应用系统
电子游戏统计数据服务
单页面、多Ajax请求Web应用
基于Node.js开发Unix命令行工具
流式数据——传统的Web应用,通常会将HTTP请求和响应看成是原子事件
不适用场景:
计算密集型应用,如视频编码、人工智能等
流量低、简单物理架构的简单 Web 应用。