在 Node.js 中,默认遵循单线程单进程模式,只有一个主线程执行所有操作。Node.js 擅长以事件驱动的方式处理 IO 等异步操作。但执行 CPU 密集型任务时,会阻塞主线程,后续操作都需要等待,此时可以通过 child_process 模块创建多个独立的子进程执行任务,多个子进程间可以共享内存空间,父子进程可以通过 IPC 通信。熟悉 shell 的同学,也可以使用它来做很多有意思的事情或工具,比如批量替换、增量部署等等。
child_process 模块
常用核心 API 有哪些?
创建异步进程
- spawn(command[, args][, options])
- execFile(file[, args][, options][, callback])
- exec(command[, options][, callback])
- fork(modulePath[, args][, options])
创建同步进程(Node.js 事件循环会被阻塞,直到衍生的进程完成退出)
- spawnSync(command[, args][, options])
- execFileSync(file[, args][, options])
- execSync(command[, options])
各参数介绍(详见 Node.js 文档)
- command: 只执行的命令
- file: 要运行的可执行文件的名称或路径
- args: 参数列表,可输入多的参数
- options: 环境变量对象
其中环境变量对象包括 7 个属性:
- cwd: 子进程的当前工作目录
- env: 环境变量键值对
- stdio: 子进程 stdio 配置
- customFds: 作为子进程 stdio 使用的文件标示符
- detached: 进程组的主控制
- uid: 用户进程的 ID.
- gid: 进程组的 ID.
你了解 child_process 模块的内部构造和 API 实现原理吗?
以下为 child_process 核心 API 的调用栈关系图

通过以上调用关系,可以看出底层实现为 process_wrap、spawn_sync 等 C++
js 外部模块中 spawn 和 spawnSync 的简化实现
在 lib/child_process 中,是如何实现 spawn 和 spawnSync 的呢,通过以下简化源码可以看出,这两个函数的实现存在一个相同的步骤:
- 标准化参数配置,包括参数默认值、属性合法性校验和处理等等
- 调用底层 Node API 提供的函数,并传入(1)中标准化后的配置项
- 返回执行体或者执行结果
1 | function spawn(file, args, options) { |
源码详见 child_process.js
js 内部模块中 spawn 和 spawnSync 是如何实现
在 lib/internal/child_process 中, spawnSync 的实现较为简单直接,调用已经加载的 NodeAPI spawn_sync.spawn 即可。
1 | function spawnSync(options) { |
ChildProcess 类的实现
ChildProcess.prototype.spawn 相对复杂些,我们慢慢拆解来看。
在了解原型函数 ChildProcess.prototype.spawn 之前,先来认识一下 ChildProcess 这个对象,他通过原型继承的方式,继承了 EventEmitter,libs/events.js, Node 中事件机制实现的基类,十分重要,十分高频,十分有用,但这里不扩展介绍,哈哈哈~
说道这里,一起看看这个类吧 ChildProcess
1 |
|
除了 ChildProcess.prototype.spawn 外,还有 kill, ref, unref 等原型函数设置,其本质还是封装调用 this._handle 上对应的 kill, ref, unref 函数,将这些内部方法暴露给 ChildProcess 的实例,这里不再做过多介绍。
ChildProcess 的原型函数 spawn 都干了什么
了解过 ChildProcess 类后,你大概已经有些明白了,child_process 中大部分核心处理都依赖与一个 C++ 模块 process_wrap 中 Process 类的实例 this._handle, 它是 ChildProcess 的一个内部属性。
同理 ChildProcess.prototype.spawn 也是如此,来具体看下它做了哪些事情。
1 | ChildProcess.prototype.spawn = function(options) { |
整体结构还是比较简单的,依次分为几个部分:
- 处理和校验 options,并为流处理做准备
- 调用 Process 类的 public 函数 spawn,得到错误
- 判断错误类型作相应的处理,具体是运行时错误,emit err, 否则 throw err
- 处理 stdio 中的 pipe、ignore、wrap 等类型的 stream
- 处理 stdio,具体指将仍存活的 socket 赋给 ChildProcess 内部属性 stdin,stdout,stderr
- 如果存在 ipc,则监听 ipc 数据进行相应的通信处理
- 返回错误
看到这里,其实 JS 作为女主的这台舞剧就基本结束了,但这个结局显然不容易被接受。
所以接下来一起来看看,那个隐藏在幕后为她一直奉献的男人,C++,CC 导演是如何运筹帷幕,掌控全局的吧。
源码详见 child_process.js
JS 是如何与 Node API 交互的呢?
简单说下 Node.js 的基础架构
V8 引擎解析 JavaScript 脚本。
解析后的代码,调用 Node API。
libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
V8 引擎再将结果返回给用户。如下图。
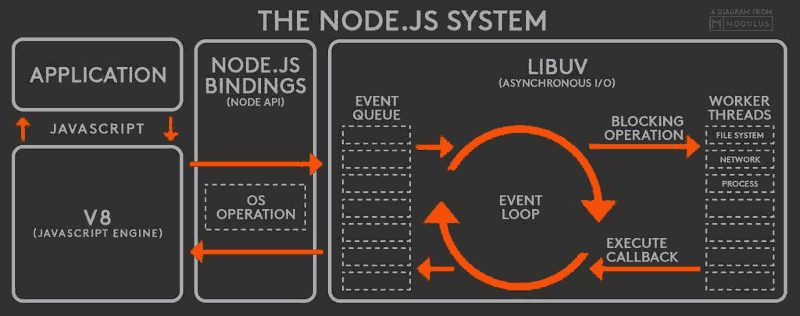
通过 internalBinding 调用 getInternalBinding 加载器
在 child_process 源码开头位置,可以看到这两段代码。
1 | const { Process } = internalBinding("process_wrap"); |
看着好像有点眼熟,代码兄 die,咱们是不是在哪见过?
1 | function spawnSync(options) { |
看到上面 👆 这两段,脑电波似乎有了一瞬间的连通~,难道说 internalBinding 就是 C++ 与 JS 传递情书 💌 的信使 🕊 吗?
是不是信使不清楚,但是 internalBinding 对于加载 Node API 确实起到了关键的作用,来看看他的实现。
1 | // internalBinding(): |
👆 函数的关键在于 getInternalBinding 的调用,按图索骥,但这个函数的实现,在 js 文件中没找到?不用担心,接着看下去。
源码详见 loaders.js
全局函数 getInternalBinding 调用原生模块
在 node.cc 文件中 BootstrapInternalLoaders 函数执行会把 GetInternalBinding 函数设置为一个名为 getInternalBinding 的 JS 的全局环境上
1 |
|
通过 👆 的函数,我们可以想到 internalBinding('module') 其实是通过 get_internal_module 来获取到对应的原生模块,接着看下 get_internal_module 这个函数。
1 |
|
很明显,get_internal_module 内部调用了 FindModule 方法,并且在modlist_internal 这个链表上,通过模块名 name 去寻找我们想要的模块。
1 |
|
FindModule 做的事情就是 for 循环找到我们想要的原生模块,然后返回。
看到这里,似乎找到了源头,但又感觉少了些什么。
是的,你的直觉没有错,确实遗漏了些东西。 相信机智的你已经意识到了几个问题。
- 什么是原生模块?
modlist_internal这个链表是从哪里来的?- 为啥它会包含我们要寻找的模块呢?
为了方便后续理解,这里 👇 我们先来解答上面的问题。
原生模块介绍
原生模块被存在一个链表中,原生模块的定义为
1 |
|
原生模块被分为了三种,内建(builtint)、扩展(addon)、已链接的扩展(linked)
- 内建(builtint):Node.js 的原生 C++模块
- 扩展(addon): 用 require 来进行引入的模块
- 已链接的扩展(linked):非 Node 原生模块,但是链接到了 node 可执行文件上
所有原生模块的加载均使用 extern "C" void node_module_register(void* m) 函数,而这里的 m 参数就是上面 node_module 结构体,不过 node_module 被放在了 node 这个 namespace 中,所以只能设置为 void\*, 函数的实现很简单:
1 |
|
看到上面 👆 这个函数,我们大概明白了,原来是通过 node_module_register 函数会将 C/C++ 模块 node_module 加入到 modlist_internal 链表中,供 get_internal_module() 使用。
C/C++知识 QAQ:
问:extern "C" 这个声明是干啥用的呢?
答:extern 是用来标明被修饰目标,即函数和全局变量,的作用范围(可见性)的关键字,使其修饰的目标可以在本模块或其它模块中使用,与 static 关键字作用正好相反。而 extern "C" 是为了实现 C++ 与 C 及其它语言的混合编程。
源码详见 node_binding.cc
那么继而产生了一个疑问,node_module_register 是在哪里调用的呢?
随意搜索一下,可以看到有 3 个文件, node_api.cc, node_binding.h, node.h,都调用了 node_module_register。
除了 node_api.cc 外,其他都是头文件中,通过宏定义来调用。
我们瞅瞅 node_api.cc 里的 napi_module_register 函数,发现它将 Node_Api_Module 转换成 node_module,然后调用了 node 这个 namespace 下的 node_module_register,将 mod 重生后的 nm 添加到链表上。
1 |
|
继续追本溯源,napi_module_register 是哪里调用的呢?
经过一番搜查后,相信胆大心细的你又 track 到 node_api.h 头文件上了。
什么情况?怎么这个也是头文件?
回想下,我们之前 track node_module_register 函数的时候,最后也是一路走到了头文件。
仔细观察会发现在 node_api.h 头文件中,napi_module_register 函数会被 NAPI_MODULE_X 这个有参宏被预处理编译时被调用。而且会在预处理编译时被导出。
其实对于 node_module_register 被调用的头文件 node.h也是类似的。
1 |
|
node_module_register 函数会被 NODE_MODULE_X 这个有参宏被预处理编译时被调用。而且也会在预处理编译时被导出。
小结:在 C++文件编译预处理后,所有原生模块会 node_module_register,添加到链表上,实现了原生模块的注册,默默的等待着前方 JS 小姐姐的 require 哦。
C/C++ 语言相关知识请参考:宏定义
源码详见 node_api.cc
深入了解原生模块
spawn_sync 实现原理
spawn_sync 模块初始化
1 |
|
通过 NODE_MODULE_CONTEXT_AWARE_INTERNAL 宏定义,在编译期调用 Initialize 函数,看下 👇 这个初始化函数做了什么事。
绑定当前环境变量下 Spawn 函数
1 |
|
Initialize 函数很简单,就 2 行代码,先获取当前的环境,然后把 Spawn 函数绑定到当前环境(JS 作用域)上,并且以 spawn 作为函数名,那么 Spawn 函数就是重点了,接着往下看。
声明 SyncProcessRunner 实例,执行 Run 方法,返回结果
1 |
|
Spawn 函数其实也比较好理解,先获取当前环境,然后声明 SyncProcessRunner 实例 p 和本地变量 result,执行 Run 方法,如果结果不存在,则停止函数继续执行,否则返回结果。
请继续看 Run 函数做了哪些事。
Run 函数通过调用 libuv 的 API 执行,得到结果并返回
1 |
|
上述 Run 函数主要调用了三个函数,TryInitializeAndRunLoop,CloseHandlesAndDeleteLoop, BuildResultObject,他们作用分别是
TryInitializeAndRunLoop:初始化生命周期,新建 loop ,执行 uv_spawn 计算结果 r
CloseHandlesAndDeleteLoop:删除 loop,修改生命周期为 close
BuildResultObject:判断结果有值,就将执行结果转化为 js 对象
小结:看完 spawn_sync 模块的源码后,我们基本了解到 Node 原生模块基本是通过调用 libuv 的 API 来执行,由 libuv 内部的事件循环统一调度,得到结果并返回。
源码详见 spawn_sync.cc
process_wrap 实现原理
创建异步进程 API spawn 逻辑回顾
先简单回顾一下,child_process 中 spawn 函数是通过调用 internal/child_process 中 ChildProcess 类的原型函数 ChildProcess.prototype.spawn 实现的,ChildProcess.prototype.spawn 中又调用了 this._handle.spawn
简化下过程为:spawn <- ChildProcess.prototype.spawn <- this._handle.spawn
我们知道 this._handle 是 ChildProcess 类的内部函数,并且是一个 Process 类的实例,而 Process 类由 process_wrap 模块提供,所以应该不难看出 this._handle.spawn 方法,是 Process 类的一个原型函数。
想通上面 👆 这部分后,咱们再来看源码就一目了然了。
初始化 process_wrap 模块
首先通过 NODE_MODULE_CONTEXT_AWARE_INTERNAL 宏调用 Initialize 函数,进行初始化
1 |
|
ProcessWrap 类源码实现
其次剩余的部分是一个 ProcessWrap 类,主要有一个 Initialize 公开函数和多个私有函数
Initialize 完成了上面 Process 类原型函数 Process.prototype.spawn 的设置
Spawn 获取 options,通过调用 libuv 的 uv_spawn 执行 loop、options 等,返回结果
1 |
|
源码详见 process_wrap.cc
简单介绍 libuv 的 uv_spawn 模块
uv_spawn 位于 deps/uv/src/unix/process.c 中的函数,是 libuv 库用来执行进程的一个方法。
uv_spawn 函数类型及参数如下:
1 | int uv_spawn(uv_loop_t* loop, |
uv_spawn 是 libuv 源码里,相当常用的进程相关的函数,有 C 语言基础,对 libuv 感兴趣可以去了解下这个 Node 实现事件循环的库,限于篇幅这里不再扩展介绍。
源码详见 uv_spawn.c
总结
本文介绍了 child_process 模块常用 API 以及其调用关系,简单扩展了 Node_API 是如何加载的,原生模块是如何注册到链表的等等,并通过简化后的源码,刨根问底,一路追溯到 spawn_sync、process_wrap 这两个 C++ 原生模块的实现,即通过 Node_API 与 libuv 的调用和交互,以 uv_spawn 函数实现上层进程的执行,并返回执行结果。
看到这里,相信优秀的你已经对 child_process 实现原理、构造,以及[ js <-> Node_API <-> libuv ]之间的交互调用关系,有了更多的认识,接下来尝试自己解析下其他 Node 模块的源码实现吧~
1 | const { spawn } = require("child_process"); |